strint
MLIR
MLIR简介
全名Multi-Level Intermedia Representation,支持创建多层IR及其转换的脚手架。
在摩尔定律时代,软件可以享受通用硬件每18个月性能翻倍带来的好处。但在后摩尔时代,为了保持加速,只能依赖针对特定业务的专用处理器,这样后端会越来越分裂,加剧软件和硬件的多对多适配的问题。
MLIR旨在通过多层IR抽象来应对软件和硬件的多对多适配问题。一个软件前端的IR,可以通过多层的IR,逐渐lowering到特定硬件上。多个中间层的IR,一来可以分层处理问题;二来一些高层次的IR和处理可以复用,低层次的IR去适配不同的硬件后端。
MLIR作为代码脚手架,能帮助提高IR的复用、IR编译的复用。但是如果原本特定业务的编译问题没有解决,那么MLIR也不能解决。
参考文献
1 动手学MLIR
MLIR中的组件,在动手的过程中,逐渐去了解。先动手,后分析,避免长篇大论,边做边学。
1.1 编译安装MLIR
推荐linux环境,这里使用的时Ubuntu。
按照下面命令,依次clone llvm仓库代码、创建build文件夹、cmake编译、自动测试。
可以看到mlir已经是llvm的子项目了,https://github.com/llvm/llvm-project/tree/main/mlir。
编译过程中,如果遇到依赖问题导致编译失败,解决好依赖问题后,最好删掉build文件夹从头编译。
git clone https://github.com/llvm/llvm-project.git
mkdir llvm-project/build
cd llvm-project/build
cmake -G Ninja ../llvm \
-DLLVM_ENABLE_PROJECTS=mlir \
-DLLVM_BUILD_EXAMPLES=ON \
-DLLVM_TARGETS_TO_BUILD="X86;NVPTX;AMDGPU" \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_ASSERTIONS=ON \
cmake --build . --target check-mlir
当看到下面的回归测试完成时,就显示你已经编译成功了:
[2844/2845] Running the MLIR regression tests
Testing Time: 30.50s
Unsupported: 170
Passed : 953
查看当前bin目录下的以 toyc 开头的文件:
ls bin/toyc*
返回:
bin/toyc-ch1 bin/toyc-ch2 bin/toyc-ch3 bin/toyc-ch4 bin/toyc-ch5 bin/toyc-ch6 bin/toyc-ch7
这些文件是后面章节中涉及的Toy语言的依赖,通过动手体验Toy语言来学习MLIR。
参考文献
1.2 Toy语言的定义和它的AST
从这部分开始,通过Toy语言了解MLIR的编译流程。Toy语言是一个玩具语言,参数是Tensor,可以定义函数、执行数学计算、打印结果。
先检查一下和Toy语言相关的文件,进入 llvm-project 目录,查看Toy语言的测试目录:
ls mlir/test/Examples/Toy/
可以看到Toy语言各个章节对应的文件夹:
Ch1 Ch2 Ch3 Ch4 Ch5 Ch6 Ch7
然后运行:
build/bin/toyc-ch1 mlir/test/Examples/Toy/Ch1/ast.toy -emit=ast
可以看到 ast.toy 程序的AST(抽象语法树)。 ast.toy 是一个toy语言的程序,经过 toyc-ch1 的处理,得到该程序的AST。
toyc-ch1 程序就是编译器中的Lexer和Parser。Lexer可以理解为把程序文件中的每个单词识别为分类型的符号(Tokens),Parser则使用类似正则表达式的机制把这些符号组合识别为各种树形表达式(AST)。下面是参考示意图(来源 https://mukulrathi.com/create-your-own-programming-language/parsing-ocamllex-menhir/)
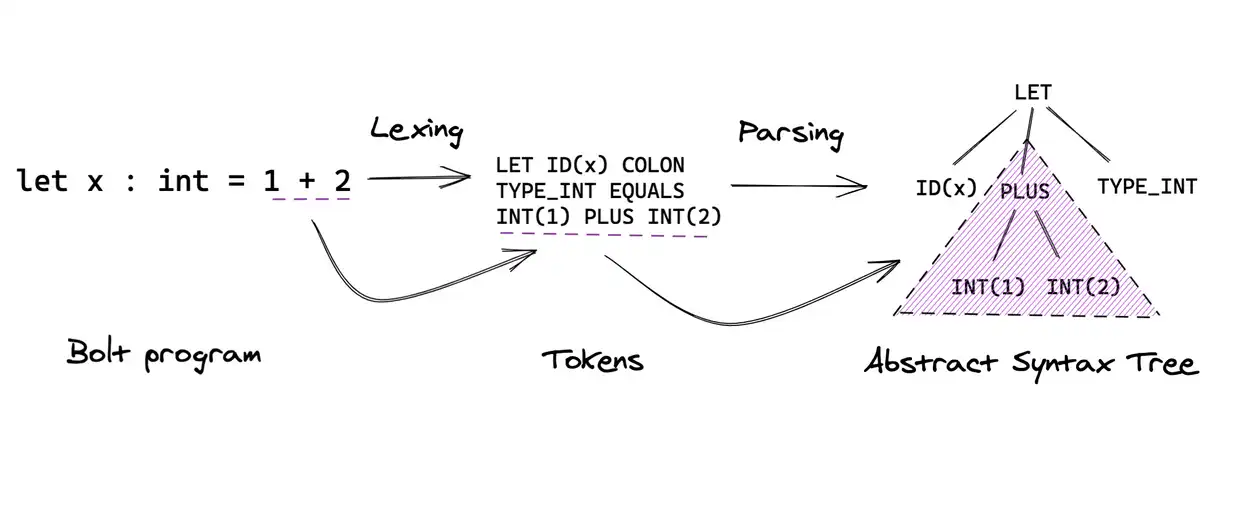
Lexer和Parser在MLIR中不关注,所以这里不再深入。后面看下Toy程序,原本的 ast.toy 比较长,这里简化下再看下它的AST,只关注Tensor、函数、计算、打印4个元素。简化的程序,命名其为 ast_simple.toy,代码内容如下:
# User defined generic function that operates on unknown shaped arguments.
def multiply_transpose(a, b) {
return transpose(a) * transpose(b);
}
def main() {
# Define a variable `a` with shape <2, 3>, initialized with the literal value.
# The shape is inferred from the supplied literal.
var a = [[1, 2, 3], [4, 5, 6]];
# b is identical to a, the literal array is implicitly reshaped: defining new
# variables is the way to reshape arrays (element count in literal must match
# the size of specified shape).
var b<2, 3> = [1, 2, 3, 4, 5, 6];
# This call will specialize `multiply_transpose` with <2, 3> for both
# arguments and deduce a return type of <2, 2> in initialization of `c`.
var c = multiply_transpose(a, b);
print(c);
}
其对应的AST:
Module:
Function
Proto 'multiply_transpose' @mlir/test/Examples/Toy/Ch1/ast_simple.toy:4:1
Params: [a, b]
Block {
Return
BinOp: * @mlir/test/Examples/Toy/Ch1/ast_simple.toy:5:25
Call 'transpose' [ @mlir/test/Examples/Toy/Ch1/ast_simple.toy:5:10
var: a @mlir/test/Examples/Toy/Ch1/ast_simple.toy:5:20
]
Call 'transpose' [ @mlir/test/Examples/Toy/Ch1/ast_simple.toy:5:25
var: b @mlir/test/Examples/Toy/Ch1/ast_simple.toy:5:35
]
} // Block
Function
Proto 'main' @mlir/test/Examples/Toy/Ch1/ast_simple.toy:8:1
Params: []
Block {
VarDecl a<> @mlir/test/Examples/Toy/Ch1/ast_simple.toy:11:3
Literal: <2, 3>[ <3>[ 1.000000e+00, 2.000000e+00, 3.000000e+00], <3>[ 4.000000e+00, 5.000000e+00, 6.000000e+00]] @mlir/test/Examples/Toy/Ch1/ast_simple.toy:11:11
VarDecl b<2, 3> @mlir/test/Examples/Toy/Ch1/ast_simple.toy:15:3
Literal: <6>[ 1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00] @mlir/test/Examples/Toy/Ch1/ast_simple.toy:15:17
VarDecl c<> @mlir/test/Examples/Toy/Ch1/ast_simple.toy:19:3
Call 'multiply_transpose' [ @mlir/test/Examples/Toy/Ch1/ast_simple.toy:19:11
var: a @mlir/test/Examples/Toy/Ch1/ast_simple.toy:19:30
var: b @mlir/test/Examples/Toy/Ch1/ast_simple.toy:19:33
]
Print [ @mlir/test/Examples/Toy/Ch1/ast_simple.toy:20:3
var: c @mlir/test/Examples/Toy/Ch1/ast_simple.toy:20:9
]
} // Block
下面从上到下列举AST中Token的含义:
- Module,一个文件代表一个模块;
- Function,一个函数定义,Proto是函数名,Params是函数参数列表;
- Block,代码块
- Return,函数返回
- BinOp: *,一个乘法二元运算的算子,该算子是toy语言定义的一个算子
- Call,函数调用
- transpose,toy语言的内置函数
- var,变量引用
- VarDecl,变量声明
- Literal,字面值常量
- @,后面是代码对应代码文件位置
- Print,print内置函数
以上含义都是比较直接的。通过上面对AST的解析,了解了Toy语言的主要元素定义。后面章节会基于该AST去生成MLIR表达。
参考文献
1.3 把AST转成一个MLIR的方言
前面一章了解了Toy语言的基本语法,这一章看如何利用MLIR编译Toy语言。
先进入 llvm-project 目录,查看下 mlir/test/Examples/Toy/Ch2/codegen.toy 代码,可以看到和第2章中的代码接近,内容如下:
def multiply_transpose(a, b) {
return transpose(a) * transpose(b);
}
def main() {
var a<2, 3> = [[1, 2, 3], [4, 5, 6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
var c = multiply_transpose(a, b);
var d = multiply_transpose(b, a);
print(d);
}
下面把该toy代码转换成MLIR表达,运行如下命令(这个命令省略了 -mlir-print-debuginfo ,因而没有loc即对应代码位置信息):
build/bin/toyc-ch2 mlir/test/Examples/Toy/Ch2/codegen.toy -emit=mlir
得到一个文本的mlir表达,我们把它叫做 codegen.mlir文件:
module {
func @multiply_transpose(%arg0: tensor<*xf64>, %arg1: tensor<*xf64>) -> tensor<*xf64> {
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>
%1 = toy.transpose(%arg1 : tensor<*xf64>) to tensor<*xf64>
%2 = toy.mul %0, %1 : tensor<*xf64>
toy.return %2 : tensor<*xf64>
}
func @main() {
%0 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>
%1 = toy.reshape(%0 : tensor<2x3xf64>) to tensor<2x3xf64>
%2 = toy.constant dense<[1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00]> : tensor<6xf64>
%3 = toy.reshape(%2 : tensor<6xf64>) to tensor<2x3xf64>
%4 = toy.generic_call @multiply_transpose(%1, %3) : (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64>
%5 = toy.generic_call @multiply_transpose(%3, %1) : (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64>
toy.print %5 : tensor<*xf64>
toy.return
}
}
执行到这里,我们已经完成了toy代码转换成AST、再转换成mlir格式这两个工作。下面对MLIR的语法做进一步了解。
回顾下第2节AST中的元素,可以猜到大致的对应关系。实际实现,也是遍历AST,一对一做AST元素到MLIR的翻译。下面我们先认识下MLIR的主要特性。
MLIR第一个主要特性是可以自定义Dialect,即自定义方言。一个Dialect,可以理解为一个IR及IR的转换的集合。IR大致包括运算类型、数据类型;IR的转换可以理解为把一种运算转换为另外一种运算。MLIR可以便捷的支持一个Dialect内、多个Dialect间的转换。
MLIR中第二个主要特性是MLIR的语法通用。内置的IR、自定义的Dialect,在格式上都符合MLIR语法。另外,只要符合MLIR语法,就可以被MLIR解析、表示、遍历,这意味着一个MLIR文件,即使其Dialect的定义没有被加载,就可做MLIR识别。这个特性被称作Opaque API。
下一节,我们去了解自定义的Dialect,这一节,我们先了解MLIR的语法。MLIR语法有三种形式,第一种是适合人阅读、debug的文本格式,第二种是适合编程转换和分析的内存格式,第三种是适合传输或者存储的经过压缩的序列化格式。三种格式语法一致,这里讨论文本格式。
前文中生成的 codegen.mlir即是mlir文本格式,我们依次阅读它。
module , 最高层级的容器操作类型,这里可以理解为一个代码文件包括的区域,区域内有多个运算操作。对应mlir中内置的的ModuleOp。codegen.mlir 中的module对应 codegen.toy 文件。 module格式为如下:
module {
}
func ,对应函数定义,后面以 multiply_transpose函数为例看下MLIR函数的语法。
@后面是函数名;- 函数名后面的括号是参数列表,参数列表中包含了每个参数及其类型,这是一种SSA形式的命名,只能通过位置去对应原函数中的参数;
- 参数列表后面是返回值类型;
- 大括号内是函数体,可以看到函数体内包括了运算调用、返回。
func @multiply_transpose(%arg0: tensor<*xf64>, %arg1: tensor<*xf64>) -> tensor<*xf64> {
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>
%1 = toy.transpose(%arg1 : tensor<*xf64>) to tensor<*xf64>
%2 = toy.mul %0, %1 : tensor<*xf64>
toy.return %2 : tensor<*xf64>
}
func 内部的包含多个运算。比如 multiply_transpose函数包含两个 transpose 、一个乘法 mul 、一个返回 return 。这些运算在MLIR语法中的运算名前面都带上了Dialect的命名空间,在这里的Dialect命名空间即为 toy ,表示 toy Dialect下的自定义运算。
MLIR中的运算的标准叫法是 Operation , 标准的调用格式如下:

toy.transpose 的调用表达看起来和上面介绍的不同,因为这个展示格式在该Operation定义时也是可以自定义的,中间的分隔符和顺序可能不同,但是都是由同样的基本元素组成的。toy.transpose 的函数签名的格式就被自定义了,格式是 (输入 : 输入类型) 属性词典 to 返回类型,如下:
let assemblyFormat = [{
`(` $input `:` type($input) `)` attr-dict `to` type(results)
}];
对应下面的 toy.transpose 后面的部分:
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>
因为可以自定义,所以Operation的格式,有时需要猜一下。
codegen.mlir 文件后面的 main 函数中没有新的语法了,不再赘述。另外Operation中有提到参数、返回值的类型,这些类型一般都可以通过名字去理解,这里也不赘述。
有了以上的知识,我们可以就可以理解基本的mlir文本格式了。下一节,我们再继续了解Dialect的自定义。
想进一步了解MLIR语法,可以参考文档,https://mlir.llvm.org/docs/LangRef/
参考文献
1.4 自定义Dialect
上一节中我们看到的Toy语言文件的MLIR文本表达,是Toy语言的AST通过Toy语言Dialect转化成的。
自定义一个Dialect,需要三大部分,第一部分是创建Dialect的元信息,主要是提供一个Dialect的命名空间;第二部分是对一个语言结构的建模,主要是定义Operation、Type、Attribute等;第三部分是提供分析、转化语言的便捷方法,主要是定义语言转化方法,也叫pass改写。后面以Toy语言Dialect为例,讲解这三个部分。
1.4.1 创建Toy语言Dialect的元信息
创建Toy语言Dialect的元信息,有两种定义方法,一种是c++代码:
/// 继承mlir::Dialect创建自定义的Toy语言Dialect
class ToyDialect : public mlir::Dialect {
public:
explicit ToyDialect(mlir::MLIRContext *ctx);
/// 方言命名空间的获取方法
static llvm::StringRef getDialectNamespace() { return "toy"; }
/// 在initialize()的实现中去注册Dialect下的自定义Operation、Type、Attribute等
void initialize();
};
另外一种是配置文件,文件格式为LLVM tablegen,文件名后缀为 .td ,该配置文件可以自动生成需要的c++文件:
def Toy_Dialect : Dialect {
// 命名空间,c++的`ToyDialect::getDialectNamespace`返回该命名空间.
let name = "toy";
// 对Dialect的简介.
let summary = "A high-level dialect for analyzing and optimizing the "
"Toy language";
// 对Dialect的详细描述.
let description = [{
The Toy language is a tensor-based language that allows you to define
functions, perform some math computation, and print results. This dialect
provides a representation of the language that is amenable to analysis and
optimization.
}];
// 该Dialect的c++命名空间.
let cppNamespace = "toy";
}
我们看下如何用tablegen的配置文件生成对应的c++文件。进入 llvm-project 目录,运行:
build/bin/mlir-tblgen -gen-dialect-decls mlir/examples/toy/Ch3/include/toy/Ops.td -I mlir/include/
这里利用了 mlir-tblgen, 用 gen-dialect-decls 说明生成Dialect的c++声明, Ops.td 文件中包含了Toy_Dialect的tablegen描述。
类似的,可以用下面的命令生成Dialect的c++定义:
build/bin/mlir-tblgen -gen-dialect-defs mlir/examples/toy/Ch3/include/toy/Ops.td -I mlir/include/
我们把ToyDialect的c++声明和定义拼接在一起看下:
namespace mlir {
namespace toy {
class ToyDialect : public ::mlir::Dialect {
explicit ToyDialect(::mlir::MLIRContext *context)
: ::mlir::Dialect(getDialectNamespace(), context,
::mlir::TypeID::get<ToyDialect>()) {
initialize();
}
void initialize();
friend class ::mlir::MLIRContext;
public:
~ToyDialect() override;
static constexpr ::llvm::StringLiteral getDialectNamespace() {
return ::llvm::StringLiteral("toy");
}
};
} // namespace toy
} // namespace mlir
DECLARE_EXPLICIT_TYPE_ID(::mlir::toy::ToyDialect)
DEFINE_EXPLICIT_TYPE_ID(::mlir::toy::ToyDialect)
namespace mlir {
namespace toy {
ToyDialect::~ToyDialect() = default;
} // namespace toy
} // namespace mlir
可以看到 initialize() 的定义是留空的,这里的需要后面补上ToyDialect下语言结构的注册,比如Operation的注册。
到这里,我们已经创建了一个Dialect的元信息类,然后需要用C++代码把它注册到 MLIRContext 里。这样就创建了一个带有 ToyDidalect 方言的mlir上下文,后面可以基于这个上下文对Toy语言做处理。
mlir::MLIRContext context;
// Load our Dialect in this MLIR Context.
context.getOrLoadDialect<mlir::toy::ToyDialect>();
另外, MLIRContext 会隐式的加载内置的Dialect,内置的Dialect提供了一些基础语言特性的集合。
1.4.2 定义Toy语言的结构
上面的ToyDialect还是个空架子,需要添加语言结构,才能表达Toy语言的运算。语言结构包括Operation、Type、Attribute等,这里我们先关注最主要的Operation定义。
Operation的定义类似Dialect,也有两种方式:C++文件、配置文件。因为配置文件使用频繁,这里只关注配置文件的用法。MLIR中使用配置文件定义Operation的格式叫ODS(Operation Definition Specification)。
在定义一个具体的Operation前,我们要先定义一个Toy语言Operation的基类,这个基类可以在 llvm-project/mlir/examples/toy/Ch2/include/toy/Ops.td 文件中找到:
class Toy_Op<string mnemonic, list<OpTrait> traits = []> :
Op<Toy_Dialect, mnemonic, traits>;
Toy_Op 继承自MLIR的 Op 基类,并提供了三个模板参数: Toy_Dialect 是之前我们自定义的Toy方言的元信息,标识 Toy_Op 属于 Toy_Dialect ; mnemonic 是op助记符,一般是op的名字; traits 是Operation特性的列表,用于标识Op一些特殊的性质,如没有副作用、输入输出的shape是否相同等。
下面我们看一个Toy语言下乘法 mul 的ODS定义,这个定义可以在 llvm-project/mlir/examples/toy/Ch2/include/toy/Ops.td 文件中找到:
def MulOp : Toy_Op<"mul", [NoSideEffect]> {
let summary = "element-wise multiplication operation";
let description = [{
The "mul" operation performs element-wise multiplication between two
tensors. The shapes of the tensor operands are expected to match.
}];
let arguments = (ins F64Tensor:$lhs, F64Tensor:$rhs);
let results = (outs F64Tensor);
// Specify a parser and printer method.
let parser = [{ return ::parseBinaryOp(parser, result); }];
let printer = [{ return ::printBinaryOp(p, *this); }];
// Allow building a MulOp with from the two input operands.
let builders = [
OpBuilder<(ins "Value":$lhs, "Value":$rhs)>
];
}
可以看了 MulOp 继承自 Toy_Op ,继承时,提供了一个 mul 这个助记符标识了Op的名字。
另外就是提供了一个Traits列表,这里列表标识了 MulOp 有一个特性是NoSideEffect,即没有副作用,这样如果Op的计算逻辑中出现和输出输出无关的操作时,编译器可以放心的把这些操作消除掉,而不用担心这些操作是有效的。
然后定义了 summary ,表示该Operation的概述;定义了 description ,表示该Operation的详细描述。
接下来的重点是 arguments ,它表示Operation的参数。有操作数和属性两种参数,每种参数都标识了其类型和参数名,其标准格式为:
let arguments = (ins
<type-constraint>:$<operand-name>,
...
<attr-constraint>:$<attr-name>,
...
);
和参数对应的时Operation的输出,格式如下:
let results = (outs
<type-constraint>:$<result-name>,
...
);
对 MulOp 来说,它声明了两个输入 lhs 和 rhs,声明了一个输出,输出名字是可选的。
接着为 MulOp 定义了 parser 和 printer ,分别用于自定义该Operation文本的解析和打印格式,这样用户可以自定义mlir文件的Operation展示格式。
最后是 builders ,它让用户可以自定义Operation实例的构建方法。实例的构建方法使得我们可以使用参数创建出一个Operation的具体实例,比如我们可以创建多个 MulOp 的实例,用于表示多次乘法运算。MLIR默认根据参数和输出创建了多种builder,如果不够,可以在这个列表里面再自定义一些。比如默认参数列表的输入是浮点数,但是你想支持从整数也可以创建该Operation,就可以自定义接受整型的builder。
自此,我们了解了一个Operation的ODS定义,MLIR工作时,会把ODS文件利用tablgen生成c++文件,即生成Operation的c++声明和定义。下面具体看下如何用tablegen的配置文件生成对应的c++文件。进入 llvm-project 目录,运行:
build/bin/mlir-tblgen -gen-op-decls mlir/examples/toy/Ch2/include/toy/Ops.td -I mlir/include/
这里利用了 mlir-tblgen, 用 gen-op-decls 说明生成Operation的c++声明。类似的,可以用下面的命令生成Operation的c++定义:
build/bin/mlir-tblgen -gen-op-defs mlir/examples/toy/Ch2/include/toy/Ops.td -I mlir/include/
如下,是mlir-tblgen根据 MulOp 的ODS生成的Operation c++声明,里面的 MulOpAdaptor 是自动生成的适配器,帮助用户去方便的访问作为参数时的 MulOp 。 MulOp 是一个Operation的接口定义,其数据实际在都在一个 Operation* 指针指向的内存中, MulOp 提供了这块内存的说明和访问这块内存的接口。
namespace mlir {
namespace toy {
class MulOpAdaptor {
public:
MulOpAdaptor(::mlir::ValueRange values,
::mlir::DictionaryAttr attrs = nullptr,
::mlir::RegionRange regions = {});
MulOpAdaptor(MulOp &op);
::mlir::ValueRange getOperands();
std::pair<unsigned, unsigned> getODSOperandIndexAndLength(unsigned index);
::mlir::ValueRange getODSOperands(unsigned index);
::mlir::Value lhs();
::mlir::Value rhs();
::mlir::DictionaryAttr getAttributes();
::mlir::LogicalResult verify(::mlir::Location loc);
private:
::mlir::ValueRange odsOperands;
::mlir::DictionaryAttr odsAttrs;
::mlir::RegionRange odsRegions;
};
class MulOp
: public ::mlir::Op<
MulOp, ::mlir::OpTrait::ZeroRegion, ::mlir::OpTrait::OneResult,
::mlir::OpTrait::OneTypedResult<::mlir::TensorType>::Impl,
::mlir::OpTrait::ZeroSuccessor, ::mlir::OpTrait::NOperands<2>::Impl> {
public:
using Op::Op;
using Op::print;
using Adaptor = MulOpAdaptor;
static ::llvm::ArrayRef<::llvm::StringRef> getAttributeNames() { return {}; }
static constexpr ::llvm::StringLiteral getOperationName() {
return ::llvm::StringLiteral("toy.mul");
}
std::pair<unsigned, unsigned> getODSOperandIndexAndLength(unsigned index);
::mlir::Operation::operand_range getODSOperands(unsigned index);
::mlir::Value lhs();
::mlir::Value rhs();
::mlir::MutableOperandRange lhsMutable();
::mlir::MutableOperandRange rhsMutable();
std::pair<unsigned, unsigned> getODSResultIndexAndLength(unsigned index);
::mlir::Operation::result_range getODSResults(unsigned index);
static void build(::mlir::OpBuilder &odsBuilder,
::mlir::OperationState &odsState, Value lhs, Value rhs);
static void build(::mlir::OpBuilder &odsBuilder,
::mlir::OperationState &odsState, ::mlir::Type resultType0,
::mlir::Value lhs, ::mlir::Value rhs);
static void build(::mlir::OpBuilder &odsBuilder,
::mlir::OperationState &odsState,
::mlir::TypeRange resultTypes, ::mlir::Value lhs,
::mlir::Value rhs);
static void build(::mlir::OpBuilder &, ::mlir::OperationState &odsState,
::mlir::TypeRange resultTypes, ::mlir::ValueRange operands,
::llvm::ArrayRef<::mlir::NamedAttribute> attributes = {});
static ::mlir::ParseResult parse(::mlir::OpAsmParser &parser,
::mlir::OperationState &result);
void print(::mlir::OpAsmPrinter &p);
::mlir::LogicalResult verify();
};
} // namespace toy
} // namespace mlir
DECLARE_EXPLICIT_TYPE_ID(::mlir::toy::MulOp)
下面是生成的 MulOp 的定义的一部分,可以看到其中一个builder的build方法,可以看到它主要在创建OperationState,OperationSate决定了一个Op的实例。
//===----------------------------------------------------------------------===//
// ::mlir::toy::MulOp definitions
//===----------------------------------------------------------------------===//
void MulOp::build(::mlir::OpBuilder &odsBuilder,
::mlir::OperationState &odsState, ::mlir::Type resultType0,
::mlir::Value lhs, ::mlir::Value rhs) {
odsState.addOperands(lhs);
odsState.addOperands(rhs);
odsState.addTypes(resultType0);
}
到这里,我们定义了一个方言,并在里面自定义了一个Operation。
参考文献
1.5 MLIR Pass改写:匹配和变换程序
编译变换一般分为局部和全局两种,本节关注局部变换。使用的设施是MLIR的Generic DAG Rewriter,它由两个主要部分组成:模式定义和模式应用,分别用于匹配模式和变换。
模式匹配和变换的定义也有两种方式。一种是命令式,即C++实现;另外一种是声明式,采用Declarative Rewrite Rules (DRR),使用DRR的约束是Operation必须是ODS定义的。下面各具一例子展示用法。
先用命令式的C++代码实现两次Transpose的化简: transpose(transpose(X)) -> X 。
先进入 llvm-project 目录,查看下 mlir/test/Examples/Toy/Ch3/transpose_transpose.toy 代码,内容如下:
def transpose_transpose(x) {
return transpose(transpose(x));
}
def main() {
var a<2, 3> = [[1, 2, 3], [4, 5, 6]];
var b = transpose_transpose(a);
print(b);
}
下面把该toy代码转换成mlir表达,运行如下命令(这个命令省略了 -mlir-print-debuginfo , 因而没有loc即对应代码位置信息):
build/bin/toyc-ch3 mlir/test/Examples/Toy/Ch3/transpose_transpose.toy -emit=mlir
得到一个文本的mlir表达,这里裁剪到只剩 transpose_transpose 函数,我们把它叫做 origin.mlir,可以看到该函数现在忠实的执行了两次transpose:
module {
func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>
%1 = toy.transpose(%0 : tensor<*xf64>) to tensor<*xf64>
toy.return %1 : tensor<*xf64>
}
}
下面我们在上面运行的命令后面加上 -opt ,代表打开优化:
build/bin/toyc-ch3 mlir/test/Examples/Toy/Ch3/transpose_transpose.toy -emit=mlir -opt
此时得到的 transpose_transpose 函数中直接返回了传入了参数,代表两次transpose操作被抵消了,这里就是本节新增的优化生效了:
module {
func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
toy.return %arg0 : tensor<*xf64>
}
}
下面看下这里的实现,首先要定义下匹配和变换逻辑:
struct SimplifyRedundantTranspose : public mlir::OpRewritePattern<TransposeOp> {
// 注册了一个匹配TransposeOp的模式
// benefit表示该模式匹配和应用的优先级
SimplifyRedundantTranspose(mlir::MLIRContext *context)
: OpRewritePattern<TransposeOp>(context, /*benefit=*/1) {}
// 当遇到一个TransposeOp,就会执行该函数
mlir::LogicalResult
matchAndRewrite(TransposeOp op,
mlir::PatternRewriter &rewriter) const override {
// 下面四行代码就是取该op的参数,看该参数是不是个transpose,不是就返回
mlir::Value transposeInput = op.getOperand();
TransposeOp transposeInputOp = transposeInput.getDefiningOp<TransposeOp>();
if (!transposeInputOp)
return failure();
// 发现本transpose
// op的输入还是一个transpose,就把本op替换为输入transpose的输入
rewriter.replaceOp(op, {transposeInputOp.getOperand()});
return success();
}
};
然后要把匹配变换逻辑注册到Transpose的规范化模式中:
void TransposeOp::getCanonicalizationPatterns(RewritePatternSet &results,
MLIRContext *context) {
results.add<SimplifyRedundantTranspose>(context);
}
另外就是TransposeOp中要标注下打开规范化模式:
def ReshapeOp : Toy_Op<"reshape", [NoSideEffect]> {
let hasCanonicalizer = 1;
}
最后就是打开规范化pass了,下面是toy文件到mlir的处理主流程:
// 加载ToyDialect
mlir::MLIRContext context;
context.getOrLoadDialect<mlir::toy::ToyDialect>();
// 加载toy源代码文件
mlir::OwningModuleRef module;
llvm::SourceMgr sourceMgr;
mlir::SourceMgrDiagnosticHandler sourceMgrHandler(sourceMgr, &context);
if (int error = loadMLIR(sourceMgr, context, module))
return error;
// 如果打开了优化,就在pass中添加规范化pass,该pass就会触发TransposeOp的规范化
if (enableOpt) {
mlir::PassManager pm(&context);
pm.addNestedPass<mlir::FuncOp>(mlir::createCanonicalizerPass());
}
// 打印mlir
module->dump();
另外,其实只加上上面的处理,得到的结果是:
func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>
toy.return %arg0 : tensor<*xf64>
}
可以看到虽然返回值是输入的 args0 了,达到了直接返回输入参数的效果,但是把 args0作为输入的第一个 transpose 没有被消除掉。这里是考虑 transpose 操作如果带有副作用,比如会原地修改输入的 args0,这个 transpose 操作是不能消除的,当然事实并不是如此。所以这里还需要把 TransposeOp 标记为没有副作用 NoSideEffect:
def TransposeOp : Toy_Op<"transpose", [NoSideEffect]> {...}
这样就可以放心的把op内和计算结果无关的操作消掉了,使得 transpose_transpose 函数被优化到直接返回传入参数。
module {
func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
toy.return %arg0 : tensor<*xf64>
}
}
参考文献
1.6 MLIR Pass改写2:基于TableGen的DRR
上一节动手试验了使用 C++ 定义 OpRewritePattern 的方式来做 Pass 改写,是一种命令式的方式。这一节采用声明式,基于 TableGen 的DRR(Declarative Rewrite Rule),使用DRR的约束是Operation必须是ODS定义的。下面使用DRR来优化Reshape。
先看一个 Reshape 程序:
def main() {
var a<2,1> = [1, 2];
var b<2,1> = a;
var c<2,1> = b;
print(c);
}
没有优化前,它的 MLIR 如下,先用 constant op 生成了一个 tensor,然后做3次 reshape,是 tensor 赋值触发的,最后做了一次打印。
module {
func @main() {
%0 = toy.constant dense<[1.000000e+00, 2.000000e+00]> : tensor<2xf64>
%1 = toy.reshape(%0 : tensor<2xf64>) to tensor<2x1xf64>
%2 = toy.reshape(%1 : tensor<2x1xf64>) to tensor<2x1xf64>
%3 = toy.reshape(%2 : tensor<2x1xf64>) to tensor<2x1xf64>
toy.print %3 : tensor<2x1xf64>
toy.return
}
}
第一个优化点是: Reshape2(Reshape1(x)) = Reshape2(x) 。即两次连续的 reshape,等价于按第二次 reshape 的要求去做一次 reshape。使用DRR时,其写法如下:
def ReshapeReshapeOptPattern : Pat<(ReshapeOp(ReshapeOp $arg)),
(ReshapeOp $arg)>;
这里学习下DRR的格式,如下所示。sourcePattern 代表用来匹配的原模式,resultPattern是改写后的模式,他们的格式都是 dag ,即 (operator arg0, arg1, ...) ;additionalConstraints 用于增加额外限制条件,benefitsAdded 是默认给了该匹配模式一个优先级。
class Pat<
dag sourcePattern, dag resultPattern,
list<dag> additionalConstraints = [],
dag benefitsAdded = (addBenefit 0)> :
Pattern<sourcePattern, [resultPattern], additionalConstraints, benefitAdded>;
可以看到,Pat 是个单输出的模式,它继承自 Pattern,Pattern 中的 list<dag> resultPatterns 代表它是个多输出的模式:
class Pattern<
dag sourcePattern, list<dag> resultPatterns,
list<dag> additionalConstraints = [],
dag benefitsAdded = (addBenefit 0)>;
按照 Pat 的格式看下 ReshapeReshapeOptPattern 的定义。 (ReshapeOp(ReshapeOp $arg)) 即 sourcePattern, (ReshapeOp $arg)即 resultPattern.
def ReshapeReshapeOptPattern : Pat<(ReshapeOp(ReshapeOp $arg)),
(ReshapeOp $arg)>;
上面自定义的双 Rashape 的消除,也要类似 C++ 自定义模式匹配和改写,在 Op 的 ODS 中允许注册规范化模式并在 Op 的 getCanonicalizationPatterns 中注册模式。这样可以把 MLIR 简化为:
module {
func @main() {
%0 = toy.constant dense<[1.000000e+00, 2.000000e+00]> : tensor<2xf64>
%1 = toy.reshape(%0 : tensor<2xf64>) to tensor<2x1xf64>
toy.print %1 : tensor<2x1xf64>
toy.return
}
}
第二个优化点是如果reshape前后的shape相同,则可以直接返回输入,对应的匹配改写模式 RedundantReshapeOptPattern:
def TypesAreIdentical : Constraint<CPred<"$0.getType() == $1.getType()">>;
def RedundantReshapeOptPattern : Pat<
(ReshapeOp:$res $arg), (replaceWithValue $arg),
[(TypesAreIdentical $res, $arg)]>;
RedundantReshapeOptPattern 使用了 additionalConstraints,对应 (TypesAreIdentical $res, $arg),来判定 ReshapeOp 的输出和输入的类型相同。TypesAreIdentical 使用了条件判断 CPred,对输入、输出的类型做了判断,要求相同时认为匹配成功。这样把 Reshape 操作直接用 replaceWithValue 标记为替换成输入参数。不过这个优化在当前的例子里,效果和双 reshape 重复了,所以看不出来。
第三个优化点是:constant 加上 reshape,可以直接变成按 reshape 的结果去运行 constant,去掉了 reshape 操作:
def ReshapeConstant : NativeCodeCall<"$0.reshape(($1.getType()).cast<ShapedType>())">;
def FoldConstantReshapeOptPattern : Pat<
(ReshapeOp:$res (ConstantOp $arg)),
(ConstantOp (ReshapeConstant $arg, $res))>;
这里为了生成 shape,调用了 NativeCodeCall,即直接在优化执行的过程中进行了 mlir 代码的执行,这样 (ReshapeConstant $arg, $res) 在经过编译优化后已经是一个 tensor 常量了。NativeCodeCall 也支持调用c++辅助函数。
加上这个优化,在编译阶段,reshape被完全消除掉了:
module {
func @main() {
%0 = toy.constant dense<[[1.000000e+00], [2.000000e+00]]> : tensor<2x1xf64>
toy.print %0 : tensor<2x1xf64>
toy.return
}
}
可以看到DRR能提供类似配置的方式来实现模式匹配和改写,为Pass改写提供了便利。