strint
TorchDynamo 初探: Python ByteCode 的动态修改
背景
深度学习框架编译优化时,需要先根据计算逻辑形成一个逻辑计算图,然后再改写计算图,最后执行改写后的计算图。其中生成逻辑计算图方式有两种。
一种计算图生成是基于 trace tensor 的,跟踪 tensor 的执行路径。tensor 执行时,基于函数重载,可以落到支持 tensor 计算的框架自定义函数,该函数一般是 c++ 层的。c++ 层的自定义函数中,功能是用于生成一个 Operation 的符号表达。比如一个对于加法运算,trace 就是记录一个符号化的加法算子。如此一连串的运算就被转换了符号化的计算图。
另外一种计算图生成是基于 AST(抽象语法树) 解析的。在代码执行前,直接根据 Python 文本代码得到 Python AST,然后根据 AST 来翻译成计算图(也叫做中间代码 IR)。
Python(特指 CPython)解释器执行,第一阶段会先把 Python 源码解析成 AST,第二阶段根据 AST 生成和优化 ByteCode(字节码),第三阶段在虚拟机中执行 ByteCode。 基于 AST 解析的计算图生成,发生在这里的第一阶段;基于 trace tensor 的计算图生成,发生在第三阶段之后。
TorchDynamo 特别的地方在于其工作在第二阶段,动态修改 Python ByteCode,这样第三阶段执行的已经是修改后的 ByteCode了。
TorchDynamo 概述
TorchDynamo 是 PyTorch 新实验的 JIT 编译接口,支持使用 Python 在运行时修改动态执行逻辑,修改的时机是 CPython 的 ByteCode 执行前。这个思想类似 DynamoRIO 项目,DynamoRIO 可以动态的修改 x86 机器码。
CPython 的每次函数调用会生成一个 Frame(或者叫 Stack),Frame 中带有的代码部分就是 ByteCode。CPython 运行时支持基于现有的 Frame 去设置一个自定义的 Frame,然后后面执行的就是自定义的 Frame。
TorchDynamo 的工作原理就是在运行时设置一个自定义的 Frame,该 Frame 中的 ByteCode 支持 CallBack 到 Python 层去修改。其提供的典型的修改接口是 FX Graph,也就是说 TorchDynamo 会分析 ByteCode 生成对应的 FX Graph,然后提供 FX Graph 的接口供用户自定义计算图。这种做法有如下优点:
- 可以支持所有的 Python 语法,因为如果在自定义 Frame 过程中的任何一点发现不支持,都可以选择不修改 Frame 而回退到原 Frame;
- 开销少,劫持发生在 Python 执行比较早的阶段(ByteCode 生成和优化阶段),而非 Python ByteCode 执行后的阶段,有时可以减少 Python ByteCode的执行开销;(猜测如果很多次 ByteCode 层面的函数调用被融合层成一次函数调用,的确可以缩减开销)
- 可以做到不增加编译带来的延迟(之前的基于 tensor trace 或者 ast 解析的做法,一般都有先编译执行所以编译开销无法掩盖,但是改写 ByteCode 这个做法,猜测是可以在识别出热点代码后,单独开一个线程去做编译,而不影响主线程工作。Python ByteCode 改写的 API 中有这种延迟编译的样例,https://peps.python.org/pep-0523/#pyjion )
CPython 的标准执行流程
上文提到了 CPython 的执行从 Python 文本代码,到 AST,到 ByteCode。这里用一个示例展开看一下。Python 的标准组件非常易用,可以在 Python 层用 ast 组件来查看 AST,可以用 compile 内置函数来编译 ByteCode,可以用 exec 系统函数来执行 ByteCode。我们先在代码开头导入相关组件:
import ast
import dis
import sys
然后我们构造一个 python 代码,可以看到 src_code 就是普通的字符串。其中包含了一段普通的 python 内置的乘法,一段深度学习的 tensor scalar 加法,最后一段是当前Python Frame 中的 ByteCode 关联对象的打印(用于一个检验,后面会提到)。
print("=== source code ===")
src_code = """
# normal python operation
x = 1
x = x * 2
# tensor operation
y = dl_framework.ones((1, 2))
z = x + y
print(z)
# print python frame
f = sys._getframe()
# print the code object
print(f.f_code)
"""
print(src_code)
然后使用 ast 组件来生成这段代码的 AST。
print("=== source code to ast ===")
# 把源代码解析成 AST
ast_obj = ast.parse(src_code)
# 打印 AST
print(ast.dump(ast_obj))
可以得到 AST,这里展示的结果额外做了格式化,另外删减掉了和计算逻辑无关的打印 frame 的部分,代码和其 AST 的对应关系参见注释。AST解析是纯文本层面的,dl_framework 还没有被 import 进来,AST解析仍然可以正常工作。AST 基本是一个多叉树的结构,每个节点对应一个表达式,节点子节点代表子表达式。以 ` x = x + 2 为例,Assign 是一个节点,是赋值运算,被赋值的是 x`,赋值的值是一个二元乘法运算。
Module(body=[
# x = 1
Assign(targets=[Name(id='x', ctx=Store())],
value=Constant(value=1, kind=None),
type_comment=None),
# x = x * 2
Assign(targets=[Name(id='x', ctx=Store())],
value=BinOp(left=Name(id='x', ctx=Load()), op=Mult(), right=Constant(value=2, kind=None)), type_comment=None),
# y = dl_framework.ones((1, 2))
Assign(targets=[Name(id='y', ctx=Store())],
# dl_framework.ones((1, 2))
value=Call(func=Attribute(value=Name(id='dl_framework', ctx=Load()),
attr='ones', ctx=Load()),
args=[Tuple(elts=[Constant(value=1, kind=None),
Constant(value=2, kind=None)], ctx=Load())], keywords=[]), type_comment=None),
# z = x + y
Assign(targets=[Name(id='z', ctx=Store())],
# x + y
value=BinOp(left=Name(id='x', ctx=Load()),
op=Add(),
right=Name(id='y', ctx=Load())), type_comment=None),
# print(z)
Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Name(id='z', ctx=Load())], keywords=[])),
# 省略了打印 frame 的代码
],
type_ignores=[]
)
Python AST 生成后,可以利用系统函数 compile 把它转成 ByteCode 字节码。解释器执行也存在编译的环节,只不过是编译成字节码。
print("=== ast to bytecode ===")
# 编译成 ByteCode
code_obj = compile(ast_obj, filename="", mode="exec")
print(code_obj)
# 展示 ByteCode 的语法糖
byte_obj = dis.Bytecode(code_obj)
print(byte_obj.dis())
print(code_obj)的结果是 <code object <module> at 0x7ff79bb5c660, file "", line 3>,这里可以看到生成的 code object 对象的指针是 0x7ff79bb5c660,后面我们在执行字节码时,会再次看到这个指针。
print(byte_obj.dis()) 的结果如下,每一行对应一条字节码,也即一条指令, 通过字面含义基本可以看出是在做什么:
# x = 1
3 0 LOAD_CONST 0 (1)
2 STORE_NAME 0 (x)
# x = x * 2
4 4 LOAD_NAME 0 (x)
6 LOAD_CONST 1 (2)
8 BINARY_MULTIPLY
10 STORE_NAME 0 (x)
# y = dl_framework.ones((1, 2))
7 12 LOAD_NAME 1 (dl_framework)
14 LOAD_METHOD 2 (ones)
16 LOAD_CONST 2 ((1, 2))
18 CALL_METHOD 1
20 STORE_NAME 3 (y)
# x = x + y
8 22 LOAD_NAME 0 (x)
24 LOAD_NAME 3 (y)
26 BINARY_ADD
28 STORE_NAME 4 (z)
# print(z)
9 30 LOAD_NAME 5 (print)
32 LOAD_NAME 4 (z)
34 CALL_FUNCTION 1
36 POP_TOP
# 省略了打印 frame 的代码
得到 ByteCode 之后,就可以传递给 Python VM 执行了。在真正执行前,先做了一下 ByteCode 中指令的打印,实际 Python VM 执行时,也基本是这样遍历每一行指令,然后执行指令。可以想象,如果这些指令被修改,就可以让 Python VM 执行自定义的指令了。
print("=== execute bytecode ===")
# print instruction
for instr in byte_obj:
print(instr.opname, instr.opcode)
# You can also do `import torch as dl_framework``
import oneflow as dl_framework
# execute bytecode
exec(code_obj)
字节码的执行结果如下。只需要在真正执行前,把 dl_framework 导入就好,然后可以看到 tensor 计算的结果,是符合预期的。
frame(或者叫 stack)是运行时的对象,对应一个函数调用的栈,在执行时被创建。 frame 中要执行的指令就是之前创建的 ByteCode。
在运行时之前,像我们之前看到的,存在一个编译时进行 AST 和 ByteCode 的编译,之前编译时生成的 code object 对象的指针是 0x7ff79bb5c660。
在运行时,可以获取当前的 frame,然后通过 frame.f_code拿到当前 frame 里面包含的 ByteCode(即 code object),可以发现它的指针就是之前编译时生成的那个。
# print(z) 的结果
tensor([[3., 3.]], dtype=oneflow.float32)
# 运行时获取当前 frame ,然后打印 frame 中的 ByteCode 对象的结果
# f = sys._getframe()
# print(f.f_code)
<code object <module> at 0x7f5cea7f1660, file "", line 3>
到此,窥见了一下 Python 源码到 AST, AST 到 ByteCode,ByteCode 到 Frame 执行这个默认的 Python 执行流程。TorchDynamo 用下图做了简单的介绍:
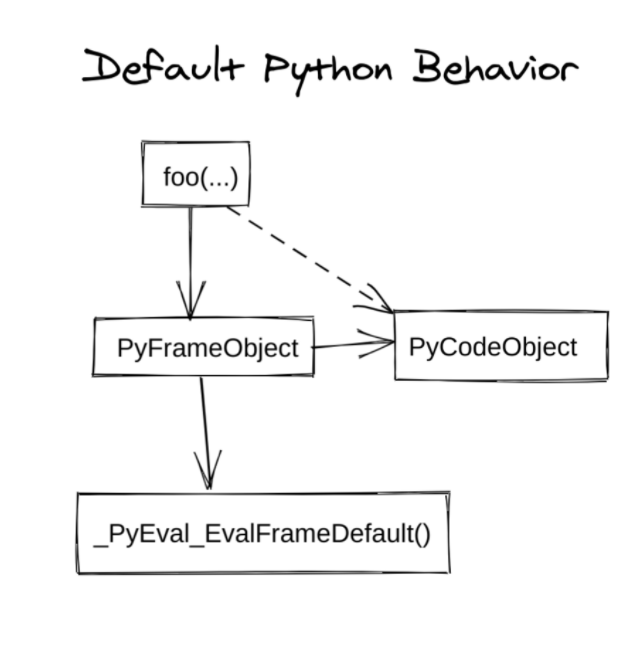
其中 foo 对应一个 Python 函数,即上文介绍的 Python Source Code。PyCodeObject 是上文介绍的 code object (ByteCode)在 C 代码层面对应的类。PyFrameObject 是上文介绍的 Frame 在 C 代码层面对应的类,它包含了代码段 PyCodeObject。_PyEval_EvalFrameDefault 对应上文介绍的 exec,它执行一个 Frame,即运行 Frame 带有的 PyCodeObject。
现在我们看一下 CPython 在 C 层面的执行 Frame 的实现,对应 _PyEval_EvalFrameDefault。它的主逻辑就是取 ByteCode 指令和执行指令:
co = f->f_code; // 从 PyFrameObject* f 中取出 PyCodeObject* ,放到 co 中
names = co->co_names;
consts = co->co_consts;
fastlocals = f->f_localsplus;
freevars = f->f_localsplus + co->co_nlocals;
// 从 co 中取出第一条指令
first_instr = (_Py_CODEUNIT *) PyBytes_AS_STRING(co->co_code);
next_instr = first_instr;
#define NEXTOPARG() do { \
_Py_CODEUNIT word = *next_instr; \
opcode = _Py_OPCODE(word); \
oparg = _Py_OPARG(word); \
// 指向下一条指令
next_instr++; \
} while (0)
// 循环执行指令
for (;;) {
// 从当前的指令 next_instr 中获取 opcode
NEXTOPARG();
switch (opcode) {
// 执行 op code,参见下个部分
}
}
每个指令类型对应一个 opcode,它是一个数值,执行 opcode,这里的 opcode 可以清晰的看到和之前我们打印的 ByteCode 的类型对应关系:
#define TARGET(opcode) \
case opcode:
switch (opcode) {
// TARGET 就是一个 case
// load
TARGET(LOAD_FAST) {
PyObject *value = GETLOCAL(oparg);
if (value == NULL) {
format_exc_check_arg(PyExc_UnboundLocalError,
UNBOUNDLOCAL_ERROR_MSG,
PyTuple_GetItem(co->co_varnames, oparg));
goto error;
}
Py_INCREF(value);
PUSH(value);
FAST_DISPATCH();
}
// store
TARGET(STORE_FAST) {
PyObject *value = POP();
SETLOCAL(oparg, value);
FAST_DISPATCH();
}
// 二元加法
TARGET(BINARY_ADD) {
PyObject *right = POP();
PyObject *left = TOP();
PyObject *sum;
if (PyUnicode_CheckExact(left) &&
PyUnicode_CheckExact(right)) {
sum = unicode_concatenate(left, right, f, next_instr);
/* unicode_concatenate consumed the ref to left */
}
else {
sum = PyNumber_Add(left, right);
Py_DECREF(left);
}
Py_DECREF(right);
SET_TOP(sum);
if (sum == NULL)
goto error;
DISPATCH();
}
// 函数调用
TARGET(CALL_FUNCTION) {
PyObject **sp, *res;
PCALL(PCALL_ALL);
sp = stack_pointer;
res = call_function(&sp, oparg, NULL);
stack_pointer = sp;
PUSH(res);
if (res == NULL) {
goto error;
}
DISPATCH();
}
}
以上总结了 Python的默认执行流程。
TorchDynamo 的工作流程
TorchDynamo 在标准的 Python 执行流程中做的主要改变就是支持修改 Frame 执行前的 ByteCode。我们暂时不关注 AST 生成,看 Python 的执行流程,是 Python Source Code -> ByteCode -> Evaluate. TorchDynamo 支持 Python Source Code -> ByteCode -> [ByteCode rewrite] -> Evaluate。
ByteCode rewrite 的工作方式是把一段 ByteCode 转成 FX Graph,然后调用用户自定义的 FX Graph 改写执行逻辑,生成一个可以经过编译的执行函数。然后把该段 ByteCode 替换成函数调用 ByteCode,而调用的函数就是经过编译的执行函数。从而实现编译优化的功能。
FX Graph 支持了再 Python 层做代码改写,提高了写 Pass 的便利性,这里做深入,可以参考1和2。
ByteCode rewrite 发生在 ByteCode 执行前。同样的 Source Code,每次执行都会走到这个步骤,都可以选择是否进行 ByteCode rewrite,或者选择进行什么样的 rewrite,还可以支持 rewrite 结果的缓存和复用。这体现了 Dynamo 的动态性。
下面看一个 TorchDynamo 下 fn() 函数编译的的例子:
# 一个普通的函数
def fn(a, b):
x = a + b
x = x / 2.0
if x.sum() < 0:
return x * -1.0
return x
# torchdynamo 函数接口
with torchdynamo.optimize(custom_compiler):
fn(torch.randn(10), torch.randn(10))
fn() 函数对应的原始的 python ByteCode,和代码对应的关系参见其中的注释:
# x = a + b
0 LOAD_FAST 0 (a)
2 LOAD_FAST 1 (b)
4 BINARY_ADD
6 STORE_FAST 2 (x)
# x = x / 2.0
8 LOAD_FAST 2 (x)
10 LOAD_CONST 1 (2.0)
12 BINARY_TRUE_DIVIDE
14 STORE_FAST 2 (x)
# if x.sum() < 0:
16 LOAD_FAST 2 (x)
18 LOAD_METHOD 0 (sum)
20 CALL_METHOD 0
22 LOAD_CONST 2 (0)
24 COMPARE_OP 0 (<)
26 POP_JUMP_IF_FALSE 36
# return x * -1.0
28 LOAD_FAST 2 (x)
30 LOAD_CONST 3 (-1.0)
32 BINARY_MULTIPLY
34 RETURN_VALUE
# return x
36 LOAD_FAST 2 (x)
38 RETURN_VALUE
经过 TorchDynamo 动态改写后的 ByteCode:
# x = a + b
# x = x / 2.0
# x.sum() < 0
# 上面两行被转换成了 __compiled_fn_0
# __compiled_fn_0 会返回 x 和 x.sum() < 0 组成的 tuple
0 LOAD_GLOBAL 1 (__compiled_fn_0)
2 LOAD_FAST 0 (a)
4 LOAD_FAST 1 (b)
6 CALL_FUNCTION 2
8 UNPACK_SEQUENCE 2
10 STORE_FAST 2 (x)
12 POP_JUMP_IF_FALSE 22
# x * -1.0 被转换成了 __compiled_fn_1
14 LOAD_GLOBAL 2 (__compiled_fn_1)
16 LOAD_FAST 2 (x)
18 CALL_FUNCTION 1
20 RETURN_VALUE
# return x
22 LOAD_FAST 2 (x)
24 RETURN_VALUE
可以看到新增了两个函数调用, __compiled_fn_0 和 __compiled_fn_1 ,这两个函数对应的代码逻辑参见 bytecode 中的注释。这两个函数对应的 fx graph 如下:
__compiled_fn_0:
opcode name target args kwargs
------------- ------- --------------------------- ---------------- --------
placeholder a_0 a_0 () {}
placeholder b_1 b_1 () {}
call_function add <built-in function add> (a_0, b_1) {}
call_function truediv <built-in function truediv> (add, 2.0) {}
call_method sum_1 sum (truediv,) {}
call_function lt <built-in function lt> (sum_1, 0) {}
output output output ((truediv, lt),) {}
__compiled_fn_1:
opcode name target args kwargs
------------- ------ ----------------------- ----------- --------
placeholder x_4 x_4 () {}
call_function mul <built-in function mul> (x_4, -1.0) {}
output output output (mul,) {}
在 ByteCode rewrite 的最后,TorchDynamo 为这一段代码的输入创建两个 Guard:
- 局部参数 a 必须是一个 Tensor
- 局部参数 b 必须是一个 Tensor
该 fn 函数被再次调用时,如果符合这两个条件,则可以命中缓存的 TrochDynamo 处理结果;否则下次 fn 执行时,会触发新的 ByteCode 分析和变换。
另外,对于和 tensor 无关的、比较特别的 python 代码,其 ByteCode 会保持原状。这样就达到了不需要用户标注区域、自动寻找优化机会的设计目标。
现在看下 TorchDynamo 执行的流程总结:
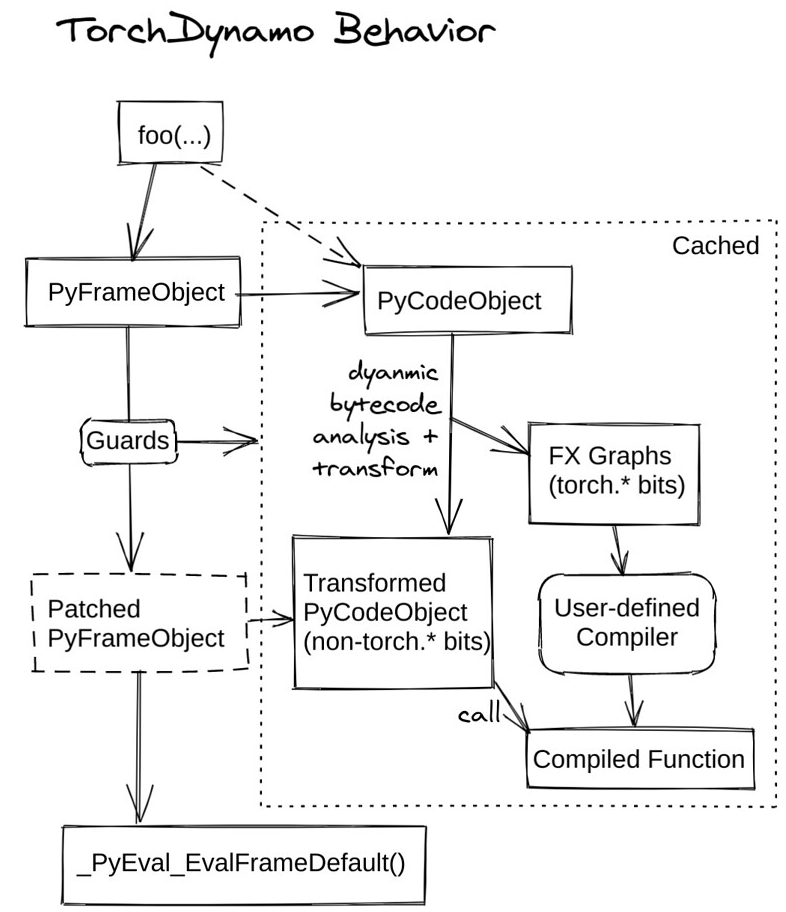
可以看到它把原来的 PyFrameObject 替换成了 Patched PyFrameObject,这个是 CPython 支持的特性。这个 Patched PyFrameObject 中最主要的改动就是 Frame 中的 ByteCode (即 PyCodeObject)被修改了,原来的 PyCodeObject 变成了 Transformed PyCodeObject。而这个被改写的 PyCodeObject 如上文和上图所示,主要是部分 ByteCode 被替换成了调用被编译过函数。这个被编译过的函数,支持自定义编译逻辑,当前默认的编译接口是 FX Graph。
这部分基本参考了Dynamo的官方介绍。
TorchDynamo 修改 Python ByteCode 的实现
Python ByteCode 修改主要依赖 PEP 523 提供的执行自定义 Frame Evaluation API。默认的 Eval Frame 逻辑入口函数是 _PyEval_EvalFrame,默认情况,它会直接调用 _PyEval_EvalFrameDefault() 来处理没被修改的 frame,但是如果发现存在一个自定义的 Eval Frame 函数,就会执行自动线的函数。
CPython _PyEval_EvalFrame 函数实现,所以只要在 ByteCode 执行前,设置一个自定义的 eval frame 函数即可:
static inline PyObject*
_PyEval_EvalFrame(PyThreadState *tstate, struct _PyInterpreterFrame *frame, int throwflag)
{
EVAL_CALL_STAT_INC(EVAL_CALL_TOTAL);
if (tstate->interp->eval_frame == NULL) {
// 这是默认的 eval frame
return _PyEval_EvalFrameDefault(tstate, frame, throwflag);
}
// 如果存在 eval_frame 就会被执行
return tstate->interp->eval_frame(tstate, frame, throwflag);
}
可以看到 TorchDynamo 正是这么做的。第一步,在 Python 层基于 ContextManger 在进入 Dynamo 作用域时,就触发 eval_frame 的设置,实现:
# torch._dynamo.optimize(...) 对应的 context manager.
class _TorchDynamoContext:
def __init__(
self,
callback: DynamoCallback,
):
super().__init__()
assert callable(callback) or callback is False or callback is None
self.callback: DynamoCallback = callback
self.prior: Union[Unset, DynamoCallback] = unset
def __enter__(self):
# 设置 eval_frame,记录之前的 eval frame
self.prior = set_eval_frame(self.callback)
def __exit__(self, exc_type, exc_val, exc_tb):
assert self.prior is not unset
# 恢复之前的 eval frame
set_eval_frame(self.prior)
这里先大致认为设置的 DynamoCallback 对应一个自定义的 eval frame 所需的参数,通常是自定义的 eval frame 中所需的编译逻辑。
看下 set_eval_frame ,C 代码层面的实现,它有点绕单最终走到了[这里](https://github.com/pytorch/pytorch/blob/eaf4fe3d2b7096579b05b52d543756f74d0e91e7/torch/csrc/dynamo/eval_frame.c#L121),也是设置 tstate->interp->eval_frame ,把 eval_frame 设置成自定义的 custom_eval_frame_shim:
// custom_eval_frame_shim 是自定义的 frame
inline static void enable_eval_frame_shim(PyThreadState* tstate) {
if (tstate->interp->eval_frame != &custom_eval_frame_shim) {
// First call
// 设置自定义的 eval frame
tstate->interp->eval_frame = &custom_eval_frame_shim;
}
}
看一下 PEP 523 提供的 Python JIT 编译器的自定义 frame 执行的样例,它提供了一个比较标准的模版(注意笔者对例子做了微调)。在自定义 eval frame 之前,一般还需要自定义一个存放自定义 ByteCode 的数据结构,可以认为是自定义的编译结果,比如样例中自定义编译结果包括3个字段:
- exec_count, 代表改 frame 被执行的次数;
- jit_failed, 代表之前 jit 编译是否失败过;
- jit_code,代表 jit 编译过后的自定义 ByteCode;
据此,来看下自定义 eval frame 的样例:
# 输入原始的 frame
def eval_frame(frame, throw_flag):
# 获取 frame 中的 code object 中的存放自定义编译结果的字段
pyjion_code = frame.code.co_extra
if not pyjion_code:
# 不如不存在,就设置一个空的默认值
frame.code.co_extra = PyjionJittedCode()
elif not pyjion_code.jit_failed:
# 如果之前 jit 执行成功
if pyjion_code.jit_code:
# 如果存在 jit 生成的 bytecode,就执行它
return pyjion_code.eval(pyjion_code.jit_code, frame)
elif pyjion_code.exec_count > 20000:
# 没有 jit 编译过,且 frame 被执行超过 20000 次,就尝试进行 jit 编译
# 如果不存在 jit 生成的 bytecode,就 jit 编译生成它
if jit_compile(frame):
# 如果 jit 编译成功,就执行 jit 编译的 bytecode
return pyjion_code.eval(pyjion_code.jit_code, frame)
else:
# 如果 jit 编译失败,就记录下,后面不再编译
pyjion_code.jit_failed = True
# 增加 frame 执行次数计数
pyjion_code.exec_count += 1
# 执行默认的 frame
return _PyEval_EvalFrameDefault(frame, throw_flag)
下面接着看 TorchDynamo 自定义 evale frame 的实现。在了解具体的自定义 frame 执行逻辑前,有个前置知识是 PyFrameObject 中的 PyCodeObject 为了执行自定义 frame 增加了一个 co_extra 字段,用来让用户放置自定义的数据,一般是存放自定义编译结果。
typedef struct {
...
void *co_extra; /* 自定义的 frame 需要的自定义数据 */
} PyCodeObject;
TorchDynamo 在自定义编译结果的类型是 CacheEntry,其中最重要的字段是 code,是被编译器修改后的 ByteCode:
typedef struct cache_entry {
// check the guards: lambda: <locals of user function>: bool
PyObject* check_fn;
// modified user bytecode (protected by check_fn's guards)
PyCodeObject* code;
// on a cache miss, linked list of next thing to try
struct cache_entry* next;
} CacheEntry;
现在看下自定义的 eval frame 逻辑 custom_eval_frame_shim:
static PyObject* _custom_eval_frame(PyThreadState* tstate, PyFrameObject* frame, int throw_flag, PyObject* callback) {
// 获取当前 frame 的 PyCodeObject 的 extra 字段用于后面设置
// 该字段用于放置自定义的编译结果
CacheEntry* extra = get_extra(frame->f_code);
// callback 即上文说的自定义编译器
// 使用 callback 进行 bytecode 的修改,即编译
// 编译结果写在了 frame->f_code中的 extra 中
PyObject* result =
call_callback(callback, (PyObject*)frame, cache_size(extra));
if (result != Py_None) {
// 缓存编译结果
extra = create_cache_entry(extra, result);
Py_DECREF(result);
// 执行自定义的 frame
// eval_custom_code 最终会调用 CPython 接口 _PyEval_EvalFrameDefault 来执行计算
// 其中 extra->code 中存放的就自定义编译器生成的 ByteCode
// 所以最终 _PyEval_EvalFrameDefault 执行的是编译器生成的 ByteCode
return eval_custom_code(tstate, frame, extra->code, throw_flag);
}
}
inline static PyObject* eval_custom_code(PyThreadState* tstate, PyFrameObject* frame, PyCodeObject* custom_code, int throw_flag) {
// 使用 custom_code 创建一个自定义的 frame
PyFrameObject* shadow_frame = PyFrame_New(tstate, custom_code, frame->f_globals, NULL);
// 调用 Python 的 frame 执行自定义 frame
return _PyEval_EvalFrameDefault(tstate, shadow_frame, throw_flag);
}
到这里,已经清楚了修改 Python ByteCode 执行的主线逻辑。
小结
这里对 Python 的执行和 TorchDynamo 的主要原理做了初探,主要是自定义 Eval Frame 的实现技巧。其它相关的 Python ByteCode 标准,ByteCode 到 FX Graph 的转换,ByteCode 的改写等内容还没涉及。
参考资料
- https://tenthousandmeters.com/blog/python-behind-the-scenes-1-how-the-cpython-vm-works/
- https://peps.python.org/pep-0523/
- https://dev-discuss.pytorch.org/t/torchdynamo-an-experiment-in-dynamic-python-bytecode-transformation/361